
27 Ноября 2018
Reading time: 5 min
Рекомендуем вам ознакомиться с первой частью данной статьи, если вы не сделали этого ранее. Вам будет в два раза интереснее и в восемь раз понятнее.
1. Алгоритмическая сложность
Ее так же называют вычислительной сложностью. В профильных вузах это понятие рассматривается достаточно подробно, мы же остановимся на краткой характеристике. Алгоритмическая сложность обозначает функцию зависимости объема работы, которая выполняется неким алгоритмом, от размера входных данных. Объем работы в данном случае обычно измеряется абстрактными понятиями времени и пространства, которые называются «вычислительные ресурсы».
Как алгоритмическая сложность влияет на разработку?
Во-первых мы имеем многообразие структур данных и алгоритмов. Всевозможные стеки, деки, деревья, В-деревья, хеш-таблицы — все это разные способы представления информации. И выбор разработчик делает в зависимости от того, какие операции в данном случае чаще будут использоваться, соответственно, он обязан в этих структурах данных ориентироваться, как рыба в воде.
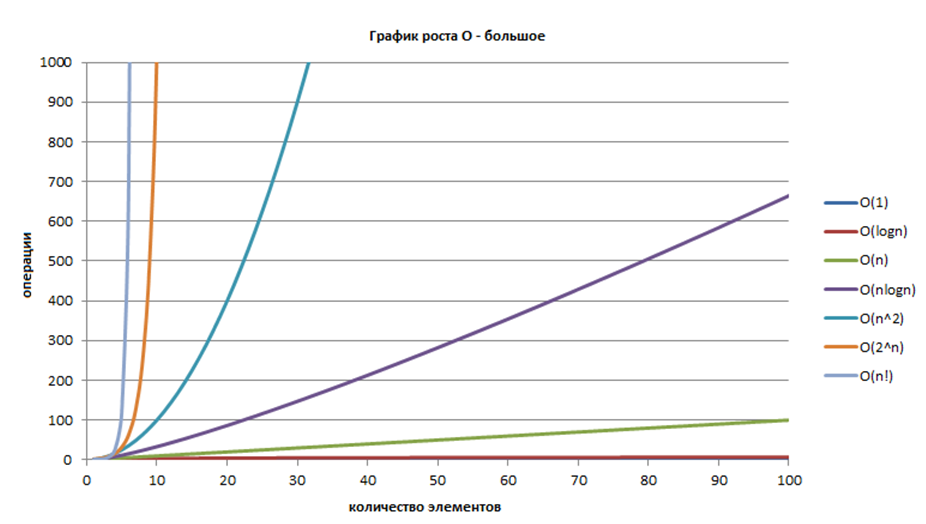
Еще одно проявление алгоритмической сложности — так называемая «проблема P=NP», она же — вопрос о равенстве классов сложности P и NP, а в русских источниках — «проблема перебора». Между прочим, уже более 30 лет держится наверху списка центральных открытых проблем теории алгоритмов.
Проблема равенства классов P и NP является одной из семи задач тысячелетия, за решение которой Математический институт Клэя назначил премию в миллион долларов США, пишет нам «Вики».
Говоря простым языком, проблема равенства P = NP состоит в следующем: если положительный ответ на какой-то вопрос можно довольно быстро проверить, правда ли, что ответ на этот вопрос можно довольно быстро найти? Или же, действительно решение задачи проверить не легче, чем его отыскать? Считается, что если на эти вопросы человечество сможет ответить «Да», то, теоретически, станет возможно многие сложные задачи решать гораздо быстрее, чем сейчас.
2. Трудоемкость разработки
На практике эта проблема выражается в том, что скорость разработки падает по мере роста проекта. Фактически — чем больше размер проекта, тем медленнее идет его разработка.
Как это влияет на работу? Во-первых, как мы уже упоминали, невозможно верно спрогнозировать сроки. Во-вторых, стремительно меняются технологии. В третьих, трудоемкость разработки становится причиной того, что программистов требуется все больше и больше, а делают они все меньше и меньше.
Что с этим делать? Целый ряд компаний умудрился этот аспект сложности обернуть себе на пользу и построить бизнес на его основе. Нет, они, конечно, не зарабатывают на том, что срывают сроки. Но они и не гонятся за конечным идеальным продуктом, а раз за разом выпускают все новые и новые версии, переделки своего ПО, которые достаются пользователям отнюдь не бесплатно.
Как было сказано ранее, на помощь многим проектам приходит Agile, который в данном случае лучше всего описывается формулировкой «если бардак нельзя предотвратить, надо его возглавить». А затем найти в нем выгоду и обернуть ее на пользу клиенту.
Кроме того, чтобы поддерживать производительность на одном уровне, есть определенные правила, называемые SOLID-принципы. Если их придерживаться, то все-таки можно добиться того, что скорость работы на проекте не будет катастрофически падать. Единственная проблема как раз состоит в том, чтобы выдержать следование этим правилам. Их всего пять и это, определенно, отдельная тема для разговора в рамках объектно-ориентированного программирования.
3. Информационная сложность
Она же — Колмогоровская сложность. Это понятие ввел в 1939 году известный советский математик Андрей Николаевич Колмогоров. Коротко ее можно описать следующим образом: информационная сложность задачи/объекта определяется количеством символов, которые необходимо записать, чтобы эту задачу решить.
То есть, фактически, сложность задачи равна количеству символов, описывающих ее решение.
Что это значит для программистов? Это, по сути, размер программы, которую они напишут для решения задачи. Понятно, что все стремятся использовать различные обозначения и приемы, чтобы уменьшить количество символов. Отсюда возникает идея, что и эту сложность можно уменьшать.
Но на самом деле все обстоит так: доказано, что определить информационную сложность задачи — это алгоритмически неразрешимая проблема. То есть, для компьютера не существует такого алгоритма, который может нам сказать, какое минимальное количество символов необходимо для решения той или иной задачи.
К чему это приводит?
Во-первых, невозможно оценивать, какого размера достигнут наши приложения.
Во-вторых, появляется все больше новых языков программирования. Возникают конструкции, которые призваны уменьшить количество символов в коде и сделать запись более компактной. И непонятно, когда этот процесс остановится: ведь мы не знаем, какое количество символов считать минимальным для описания какой-либо операции.
В-третьих, среди приверженцев различных языков регулярно возникают холивары, а также удивительно легко претворяется в жизнь «Парадокс Блаба», придуманный американским программистом Полом Грэмом. Суть в том, что программист, знающий некий язык (в данном случае, выдуманный язык «Блаб») «думает» на нем, выражает решение любой задачи его средствами, а более мощные средства другого языка обесцениваются в его глазах, так как он даже не осознает, как их применять. При этом, ограниченность «Блаба» сама по себе не может быть стимулом для изучения более мощного языка, так как для осознания этой ограниченности нужно уже знать такой язык.
Еще одна идея состоит в том, что чем больше предметная область, для которой пишется программа, чем больше задача — тем больше вырастает ее информационная сложность. И процесс по созданию более компактных записей все равно не успевает за потребностями бизнеса.
Так и получается, что программы становятся все более и более громоздкими, а задачи обладают все большей информационной сложностью.
Тут самое время вспомнить о проблеме математиков: есть теория о том, что к 2075 году доказательства станут настолько большими и длинными, что одному человеку будет не под силу за всю жизнь понять даже одно из них. Фактически — возникнет потребность в помощи компьютера, который будет эти доказательства строить.
По аналогии с математикой можно предположить, что скоро и программы станут настолько масштабными. Но предсказывать будущее с уверенностью мы не можем, поскольку вычислить их информационную сложность нельзя. Тем не менее, опять и опять возникает потребность в программах, которые будут писать за нас другие программы, а это и есть в нынешнем понимании машинное обучение.
Но, как с математическими доказательствами, так и с написанием программ есть еще одна сложность — четвертая.
4. Сложность тестирования
Она говорит нам о том, что трудоемкость тестирования программы тоже растет нелинейно, очень быстро, по мере увеличения количества входных данных.
Есть такая книга «Art of Software Testing» («Искусство тестирования программ», авторы — Гленфорд Майерс, Том Баджетт, Кори Сандлер), первое издание которой вышло в 1979 году. В этой книге приведен пример программки буквально из ста строчек кода, которая имеет 10 в 10 степени вариантов выполнения. Если потратить на проверку каждого варианта по 5 секунд, то у тестировщика уйдет на эту работу больше времени, чем существует планет Земля. В общем, в масштабах человеческой жизни для нас это все равно что вечность.
В действительности, потребность в ресурсах по тестированию ПО тоже очень и очень высока. И, фактически, мы вынуждены мириться с тем, что в каждой программе может быть ошибка. И что все эти программы не совсем корректно работают, потому что мы не можем доказать обратного.
Экскурс в историю
Попытку найти выход из сложившейся ситуации предпринял в 1969 году Чарльз Хоар, выпустив статью «Аксиоматический базис языков программирования». Им была предпринята попытка аксиоматизации, то есть предъявления формальной логической системы, с помощью которой можно было бы доказывать корректность программ. Изначально результаты были очень хорошие, пока все работали на уровне if-ов, циклов и т. д. Но при переходе к процедурному программированию все «сломалось».
Выяснилось, что предлагаемые системы аксиом, описывающие процедуры, как правило, приводят к противоречию. И в 80-м году вышла статья «Критика логики Хоара», которая с помощью контрпримеров поставила крест на его аксиоматическом базисе.
На самом деле, противоречие в данном случае зашито в само понятие вычислимости и связано с проблемой остановки машины Тьюринга. Нет алгоритма, у которого по входным значениям можно было бы определить, зациклится он или нет. И вот эта проблема остановки машины Тьюринга как раз приводит к противоречивости аксиом, а противоречивая аксиома, увы, позволяет нам доказать абсолютно любое утверждение, как верное, так и не верное.
Если бы аксиоматический подход оправдал себя, то можно было полностью автоматизировать процесс верификации программ, но в данный момент это невозможно.
В итоге мы имеем вот что: трудоемкость растет, размеры программ растут, возникает потребность в мета-программировании, в частности, в использовании «искусственного интеллекта», машинного обучения, но мы не можем гарантировать и того, что наш ИИ или «специально обученная» программа будет работать правильно, потому что не можем это досконально проверить.
Таким образом, существуют 4 глобальных проблемы, которые сильно влияют на IT-отрасль, и пока есть только два выхода — либо бежать вперед как можно быстрее, как говорила Черная королева, либо «ничего не решать». Это же бизнес, а значит будет постоянная потребность в программистах, которые будут писать и верифицировать что угодно, в том числе, ИИ.
И справедливы сомнения о том, что искусственный интеллект вытеснит живых разработчиков, потому что по-прежнему любая подобная система не способна рефлексировать, то есть оценивать результаты своей деятельности, а значит нужен человек, чтобы хоть как-то понимать, работает ИИ верно или нет.
Звучит как сюжет фантастики, но, в противном случае в какой-то момент мы можем обнаружить, что наш искусственный интеллект считает, что люди — это лишнее звено на планете Земля. А почему нет? Загрязняют окружающую среду, растрачивают природные ресурсы, неконтролируемо размножаются и больше любят разрушать, чем созидать. Тем не менее, мы для себя считаем это утверждение ложным, а ИИ сочтет его истинным. Но на самом деле, глобальный вопрос к искусственному интеллекту даже не в истинности и ложности его суждений, а в том, выгодны нам его утверждения или не выгодны. И это действительно сложно: тут просто проверить-то утверждение нельзя, а еще и выгоду нужно закладывать.
Также, в силу того, что в логике ИИ могут возникать ошибки, сложно говорить о том, что он в обозримом будущем появится в каких-то особо опасных отраслях.
Но беда в том, что разрабатывая подобные системы, мы иногда забываем, что не обязательно давать машине возможность управлять атомной станцией, чтобы случилась катастрофа. Для того, чтобы устроить апокалипсис, ИИ будет достаточно, например, по ошибке отключить электричество по всей планете. Или одновременно выключить все лифты. Или заказать пиццу. Оценить последствия любой ошибки в таких масштабах практически невозможно, информационная сложность нам не дает этого понимания.
И если люди, с энтузиазмом ошибаясь ради общего блага, сами создают разрушительные для мира вещи, например, ядерное оружие, то с вычислительной мощью искусственного интеллекта помноженной на желание создать нечто выдающееся, уничтожить мир можно гораздо быстрее — и весьма нетривиальными способами.
Читайте также




